Amazon Web Services
AWS is the cloud service provider we use for cloud computing, storage, and database services. Making things happen in AWS, like creating databases or servers, and especially making them communicate is a skill in itself. This page contains documentation on how we use AWS and all of the component services that we are currently leveraging.
The AWS Console
This is the command center for all of the below listed services. From this platform we can create new servers, manage security and networking, view our billing and so on and so on.
To get admin access, we need to login to our master account (esf.beier.lab@gmail.com), and:
- navigate to the “IAM Identity Center”
- add a new user (email)
- add that user to our “admin_cafri” group
Lucas has access to the master account (which controls our CAFRI AWS account and a few others), and can provide login details if needed, but outside of adding users we probably shouldn’t be playing in this master account.
Architecture
There are three main components to our AWS cloud infrastrucure. We have compute instances (see EC2/lightsail below), with object storage, which is essentially just files in buckets and folders (see S3 below), and Postgres databases (see RDS below) with Postgis (providing spatial operations). We give compute instances access to both S3, and RDS, but S3 and RDS can’t communicate with one another. 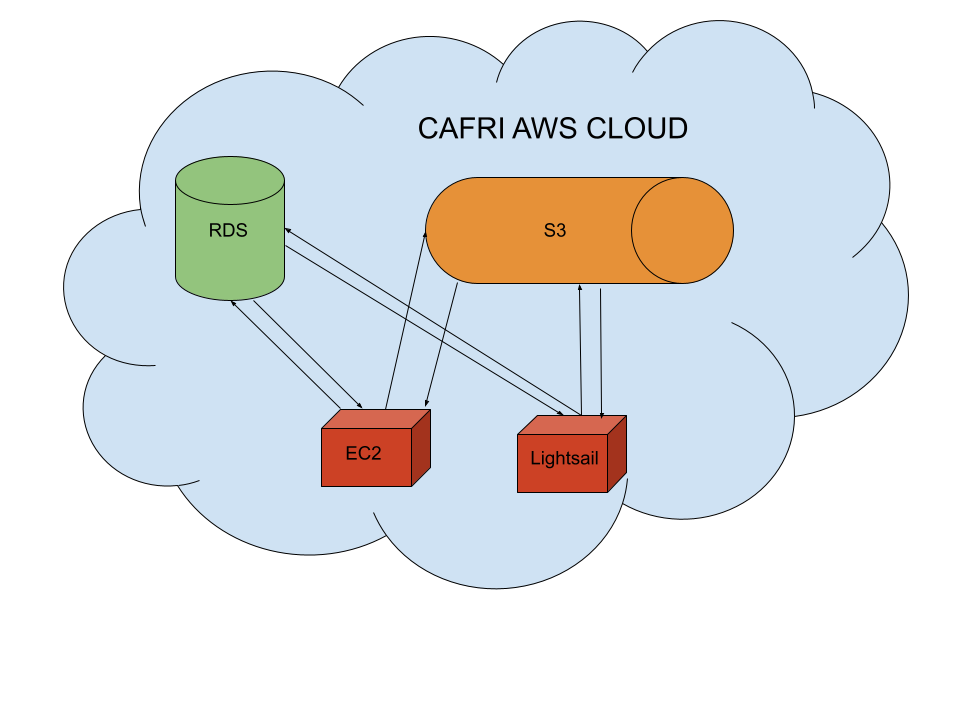 The two data storage systems (RDS, and S3) are mostly locked down by design, only allowing access from within our virtual private cloud (see Networking section below). This means to access data in our cloud, make changes, upload new data, or really do anything with our cloud stored data you need to first access one of our compute instances via ssh. While this is a super simple and secure design with only one method of entry via ssh, it’s quite restrictive, and we might be interested in providing direct access to our S3 or RDS services, though we haven’t gotten there yet. labrador is the main exception to this rule, allowing users to pull down a pre-defined set of data from S3 directly to their local machines.
The two data storage systems (RDS, and S3) are mostly locked down by design, only allowing access from within our virtual private cloud (see Networking section below). This means to access data in our cloud, make changes, upload new data, or really do anything with our cloud stored data you need to first access one of our compute instances via ssh. While this is a super simple and secure design with only one method of entry via ssh, it’s quite restrictive, and we might be interested in providing direct access to our S3 or RDS services, though we haven’t gotten there yet. labrador is the main exception to this rule, allowing users to pull down a pre-defined set of data from S3 directly to their local machines.
While S3 and RDS do not ‘communicate’ directly, a common practice is to store a set of geometries (exents) of a tiled dataset in Postgres (RDS), with a field containing a link to that tile’s location in S3 storage. That way we can make spatial queries (not supported by S3) to get a set of tiles, and then download them from S3 where large datasets, like high-resolution rasters or dense point clouds, can be stored relatively cheaply. There is a way to store rasters (or other) directly in Postgres, but I have found retrieval/downloads to be quite slow, and I imagine our RDS bills would be quite high.
Main Services
EC2
This service includes all of AWSs cloud compute (that’s where the C2 comes from; the E is for elastic…) instances. You can pick from a range of templates, specifying RAM and CPUs, and you can allocate SSD storage space as you go. Different payment plans are available, with savings for longer term contracts (1 year, 2 years). We always operate on the hourly rate, as we turn off our instances when we are done using them. This is a bit tedious to do, but we really eb and flow with how often we use these, so the hourly rates still make sense from a cost perspective - so long as we don’t forget to turn them off…
To access these boxes: a) spin up a new instance from the admin console, at which point you’ll have to enter an SSH key pair which will then allow you to SSH in when the instance is ready OR b) request access to one of our existing instances. Whoever already has access will need to start the instance, ssh onto the box, and add your public key to the ~/.ssh/authorized_keys file.
S3
This is AWSs ‘simple storage service’ (hence s3). We use this primarily for storing LiDAR point cloud tiles and raster tiles, but have a few other datasets laying around. You can access any of this data by logging into the admin console, and can even download to your local machine this way. But it’s not very efficient.
EC2 instances with the ‘ec2_full’ role (see Networking section) have access to all s3 data, and can efficiently upload/download data using the s3 CLI. labrador has access to everything in the ‘cafri-share’ bucket. Items with spatial components (tiles) will likely have a corresponding record in our Postgresql server, and can/should be queried that way (i.e. labrador / lidar point clouds).
RDS
This is AWS’s relational database system (hence RDS). We currently have 1 relational database. It is a Postgresql db with postgis installed like this.
Access this database from our labrador (lightsail) server or any EC2 instances inside of the same virtual private cloud (see Networking below) using the credentials (user and password) for ‘rds-master’ stored in AWS secrets manager service. The hostname is listed in the RDS console. The following command from the CLI will request the password and give you access:
psql -U <insert user> -h <insert hostname>Lightsail
This is the service we use to host labrador. It offers much less configuration than EC2, with generally lower performance (RAM/CPU), but is much cheaper. Since we want labrador to be on all the time, and we don’t expect it to be doing any real heavy compute, we use this service. The labrador server is primarily access via ssh. To get ssh access:
- login to the admin console
- navigate to the Lightsail service
- navigate to the ‘labrador’ instance
- under ‘Connect’, find ‘Use your own SSH client’, and download the default key. Save this key in your ‘~/.ssh’ folder (applies to MacOS and Ubuntu… not sure on windows).
- then navigate to the ‘Networking’ tab, still under the ‘labrador’ instance.
- To whitelist your IP address, add a rule to the ‘IPv4 Firewall’ section under ’SSH”, and save.
Secrets Manager
This is a service that stores named credentials or ‘secrets’. The service can be accessed through the AWS console, allowing us to add/remove or access credentials. But the real benefit, beyond having a single place where we can go find our creds, is that we can access them programmatically This allows some of our compute instances, those we grant permission, to read these creds when they need them. Our main use case is for labrador to look up credentials to our Postgresql database.
Networking
VPC
AWS uses virtual private clouds (hence VPC) to create logically isolated networks in the cloud. Our EC2 and RDS resources live within a single VPC for simplicity. S3 stuff is fully managed by AWS and lives outside our custom VPC so access S3 is controlled a bit differently (see IAM section).
We use security groups to control traffic within our security group. Without specific security groups applied to specific instances (EC2/RDS), all traffic within our VPC is allowed (inbound and outbound). For example we have a security group (called dev-ssh) which we apply to all of our our EC2 instances, which only allows ssh ingress. For our RDS instance we have a security group (called db-private-labrador) which only allows ingress from our labrador IP address or any other resource within our VPC. You can create additional secuirty groups, add/remove rules from existing groups, or apply/remove security groups from individual instances through the AWS console.
Find more documentation on AWS VPCs here.
IAM
Identity and access management allows us to grant access to services that operate outside of the VPC settings. These services include things like the AWS secrets manager and S3. Roles have one to many relationships with instances, allowing us to assign the same role to several instances (like ec2 instances). Users are for specific entities like (labrador). For EC2 instances, roles can be assigned in the AWS console. For lightsail instances access keys need to be generated for the role/user, and the following needs to be added to the ~/.aws/credentials file on the box:
[default]
aws_access_key_id = <your access key ID>
aws_secret_access_key = <your access key>Current examples include the following:
- Role: ‘ec2_full’ grants EC2 instances with this role full access to S3 and read access to AWS Secrets Manager.
- User: ‘labrador_user’ grants our lightsail instance read access to S3 and read access to AWS Secrets Manager.